
In 2023, the super-large-scale multi-modal pre-training model & mdash;& mdash; Was released GPT-4, which quickly detonated the Internet. After that, OpenAI, Microsoft, Google, Huawei, Baidu, Shangtang, byte beat, etc. entered the arena one after another to launch their own big models. AI big models officially entered the era of blooming flowers.
In essence, AI big models support various applications through "pre-training" and "big models" based on a large amount of data. AI big model parameters range from billions to trillions. Data is the most critical asset in data acquisition, pre-training, modeling, and other aspects. The reliability of the data determines the accuracy of the training results. Data is exactly the most vulnerable value asset in the AI big model era. Under the new situation, how to ensure the reliability and security of data has become an unavoidable problem.
Data security of AI models faces two major challenges
challenge 1: New attacks occur and data reliability is difficult to guarantee
in the AI era, new security attacks such as ransomware, poisoning and theft began to emerge, threatening the reliability of big model training data and the accuracy of results and causing serious economic losses.
First, blackmail software attackers encrypt data, causing computing power clusters to fail to read and use data normally. As large model training involves expensive infrastructure investment, it costs more than one million yuan per day, after the suspension of training, the economic losses were huge.
Second, blackmail attacks are accompanied by data leakage. After attackers steal key assets such as model results and data, they sell them publicly in the dark network, causing serious losses to enterprises. In March 2023, big Meta models were leaked. In the following week, similar big models such as Alpaca, ChatLLama, ColossalChat, FreedomGPT appeared one after another. Meta was forced to announce open source, and the previous investment was in vain, resulting in heavy losses.
Third, a new type of network poisoning attack appears. Attackers mix malicious data samples into the training data and eventually interfere with the training results at minimal cost, resulting in distortion or even invalidity of the training results of large models. According to research by the University of Melbourne and Facebook, only 0.006% of malicious samples are needed, and there is a 50% probability of data poisoning attacks.
Challenge 2: large training data capacity, high data protection costs and difficulties
take a well-known AI manufacturer in China as an example. In the data training and modeling scenarios, the data size has reached 5PB and 250TB respectively. The emergence of Sora marks that the AI model has moved from NLP to multi-modal, increasing the data size and data preprocessing complexity. Taking Sora and Gemini as examples, the training data involves up to 100PB of images, audio, and video. With the evolution from trillions of multi-modes to trillions of multi-modes, the data scale is even as high as EB level. Facing PB-level and even EB-level data protection, performance and cost have become urgent problems to be solved in data security in the AI era.
It is imperative to protect both internal and external data.
How to ensure data security and reliability in the AI big model era? The author believes that it is nothing more than practicing muscles and bones outside, practicing one breath inside and practicing both inside and outside to enhance the robustness of data. Practice external muscles and bones, emphasize external strength, enhance security and reliability through external means, such as data backup, isolation zone copy retention and other other AI storage systems; Internal practice emphasizes endogenous security, enhance the native security and robustness of data through internal means, such as security snapshots, immutable replicas, and deep defense.
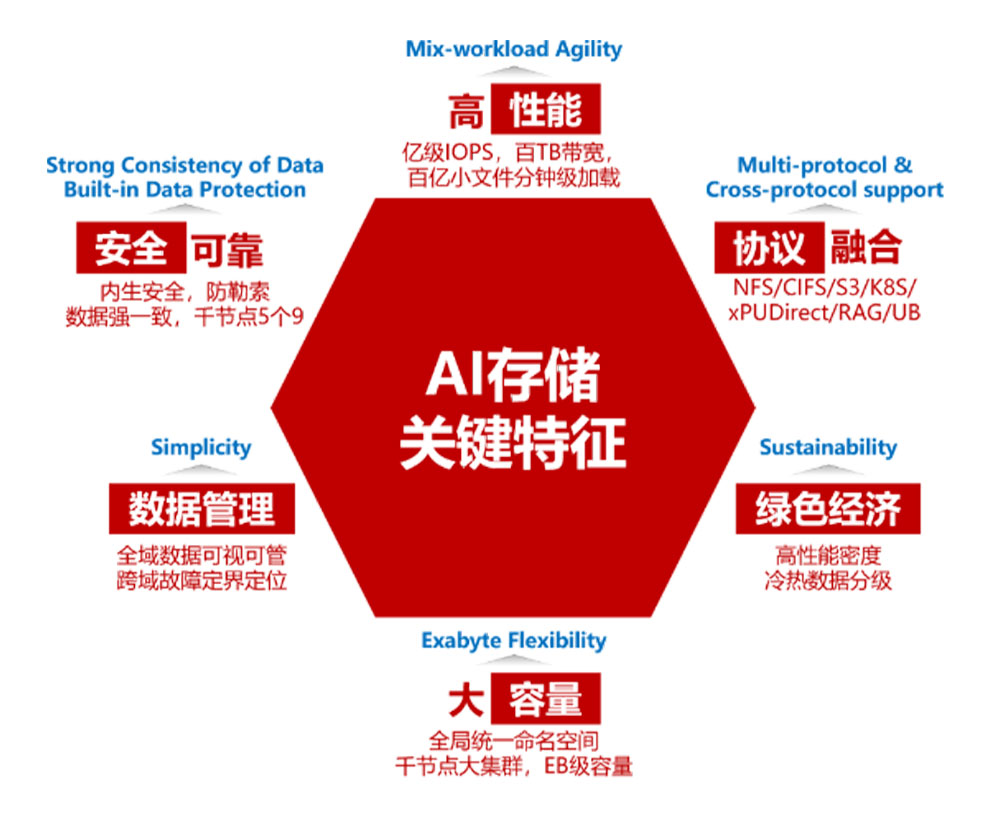
Figure 1 security and reliability are key features of AI storage
the most effective way to refine muscles and bones is to back up data.
For external training, the most common method is to efficiently back up key data. In terms of the industry, data backup all-in-one machines are usually used. Based on traditional backup capabilities and facing AI scenarios, the author believes that the all-in-one data backup machine needs to adopt a variety of technologies to address the pain points of large data capacity, high data protection costs and high difficulty in the AI era:
full Flash media can be used to speed up data protection for AI big models. In recent years, the single SSD disk density has continuously increased, and the current single disk capacity is as high as 61.44TB, which is three times the HDD capacity. With large SSD media capacity and high performance, it is the best choice to accelerate data backup in the AI era. Huawei provides OceanProtect all-in-one backup machines based on 30.72TB/61.44TB full flash disks, which can improve the backup and recovery performance by more than three times and meet the demanding backup time window requirements.
The algorithm is updated to further improve the data reduction ratio of the backup all-in-one machine: based on the source-side re-deletion, the target-side re-deletion continuously iterates the update reduction rate algorithm to reduce the overall cost of ownership. Huawei OceanProtect all-in-one backup machine supports up to 72:1 data reduction and continues to evolve to> 100:1. In the case of PB-level backup data sources, it can minimize the storage space occupied by backup data, reduce the cabinet space in the data center, reduce energy consumption, and achieve the goal of energy conservation and emission reduction.
Data desensitization to ensure AI data security: in the AI era, the risk of privacy disclosure always exists. Before the backup data is reused, you can desensitize sensitive data such as person name, ID, and password to reduce the risk of privacy data leakage, maximize the security of backup data replica reuse and meet compliance requirements such as PCI-DSS and HIPAA.
Internal practice one Breath focuses on endogenous safety protection
the internal practice focuses on building the endogenous security capability of the data infrastructure. On the one hand, it is guaranteed based on the native protection measures of the storage system, such as blackmail detection, to ensure the reliability of AI data sources; On the other hand, it builds a multi-level and three-dimensional network and storage linkage capability to form deep defense, provides the best protection for AI big model data.
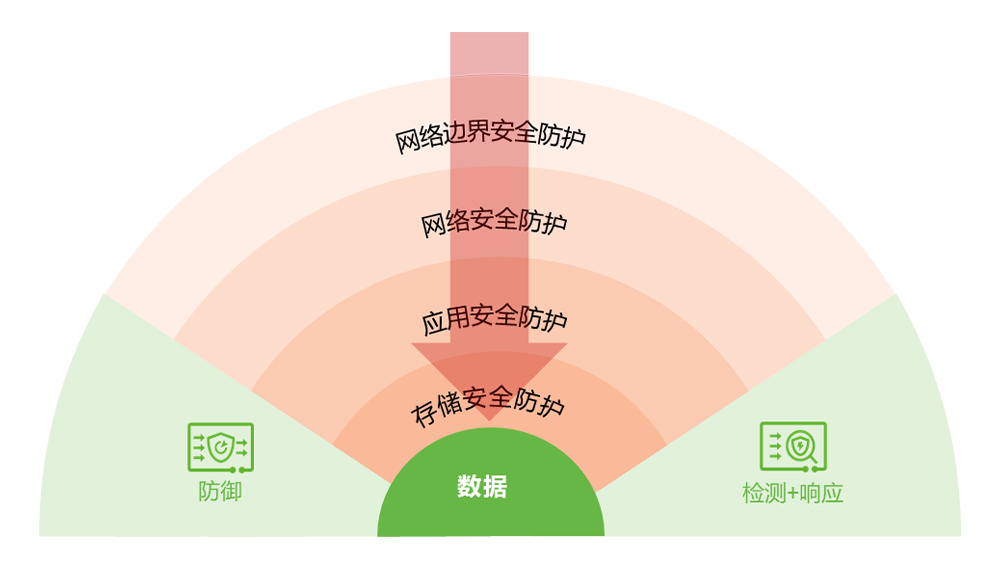
Figure 2 network-to-store linkage creates the strongest three-dimensional protection for AI models
building multi-level three-dimensional defense capabilities usually has the following advantages:
network-to-network linkage is more timely: when the network side detects an abnormal intrusion, it triggers an alarm and sends it to the storage side synchronously. The storage side takes corresponding protection measures based on the severity of the alarm, such as high, medium, and low, such as security snapshots, disconnects the isolated zone network and so on to make the response more timely;
bait files are more accurate: traditional storage layer defense mainly uses passive methods such as blacklist/whitelist management and post scan to deal with ransomware attacks. The bait file can trigger and identify blackmail software in advance by simulating writing sensitive data, thus turning passive into active, further improving the protection level and realizing accurate detection.
Deep defense is more reliable: through the construction of multi-level deep defense system, it extends the path of analyzing ransomware attacks, maximizes the ability of detecting and identifying ransomware attacks by various defense lines, and superimposes independent backup copies and isolated copies of all-in-one backup machines, finally, malicious software attacks can be identified, prevented, and easily recovered, effectively ensuring data security. Huawei adopts the network-side and storage-side linkage scheme. Through layer -6 defense, the accuracy rate of blackmail attack detection can reach 99.99%.
Both internal and external data protection helps AI enable thousands of industries
the AI model continues to accelerate iteration, increasing the parameter size and data volume by tens of thousands of times. Data reliability and security are two unavoidable topics in the era of AI big models. Only by building a data protection system with both internal and external repairs can we effectively support the training requirements for PB ~ EB data, ensure the accuracy of the training results, and finally support and enable the application of thousands of industries.
Disclaimer: the content and opinions of the article only represent the author's own views, for readers' reference of ideological collision and technical exchange, and are not used as the official basis for Huawei's products and technologies. For more information about Huawei's products and technologies, visit the product and technology introduction page or consult Huawei's personnel.
