In 2023, the release of GPT-4, an ultra-large-scale multimodal pre-trained model, quickly ignited the Internet. Since then, tech giants like Microsoft, Google, Huawei, Baidu, SenseTime, and ByteDance have launched their own large AI models, ushering in a flourishing era of AI innovation.
Large AI models are fundamentally built on vast amounts of data and support a wide range of applications through pre-training and foundation models. These models rely on billions to trillions of parameters, making data the most crucial asset in data acquisition, pre-training, and modeling. The reliability of data directly impacts the accuracy of training results. However, in the age of large AI models, data is also increasingly vulnerable, making the challenge of ensuring data reliability and resilience both critical and unavoidable.
1. Data Resilience Challenges Faced by Large AI Models
Challenge 1: Emerging attack methods threaten data reliability
In the AI age, new resilience threats like ransomware, data poisoning, and data theft jeopardize the reliability of large AI model training data, compromising the accuracy of results and leading to significant financial losses. How does this occur?
Malicious actors encrypt data, making it inaccessible to computing clusters. Since large-scale training involves substantial infrastructure investments and daily costs exceeding CNY1 million, any interruption in training can result in massive financial losses.
Ransomware attacks often involve data leaks, where attackers steal and sell key assets like model results and data on the dark web, causing significant damage to enterprises. For instance, in March 2023, Meta's large language model was leaked, leading to the rapid emergence of models like Alpaca, ChatLlama, ColossalChat, and FreedomGPT. This breach forced Meta to open-source their model, rendering its investments worthless.
Furthermore, new types of network poisoning attacks are on the rise. Attackers add malicious data samples into training datasets, distorting or invalidating training results at a very low cost. Research from the University of Melbourne and Facebook shows that only 0.006% of malicious samples are needed to achieve a 50% success rate in data poisoning attacks.
Challenge 2: High costs and complexity of protecting large training and inference data volumes
Consider a leading AI vendor in China: in data training and modeling scenarios, the data scale can reach 5 petabytes and 250 terabytes, respectively. The advent of models like Sora marks a shift from natural language processing to multimodal AI models, exponentially increasing data scale and preprocessing complexity. For instance, Sora and Gemini require up to 100 petabytes of training data, including images, audio, and videos. As multimodal AI models evolve from processing trillions to tens of trillions of parameters, data scales reach the exabyte level. Protecting petabyte- and exabyte-scale data presents urgent challenges in terms of performance and cost in the AI age.
2. A Data Protection System with Internal and External Resilience Is Imperative
How can we ensure data resilience and reliability in the large AI model age? I believe strengthening data robustness requires both external and internal measures. External measures involve enhancing system resilience and reliability by implementing data backups and isolated-zone copy retention outside the AI storage system. Internal measures, on the other hand, focus on boosting intrinsic data resilience and robustness through secure snapshots, immutable copies, and layered defenses.
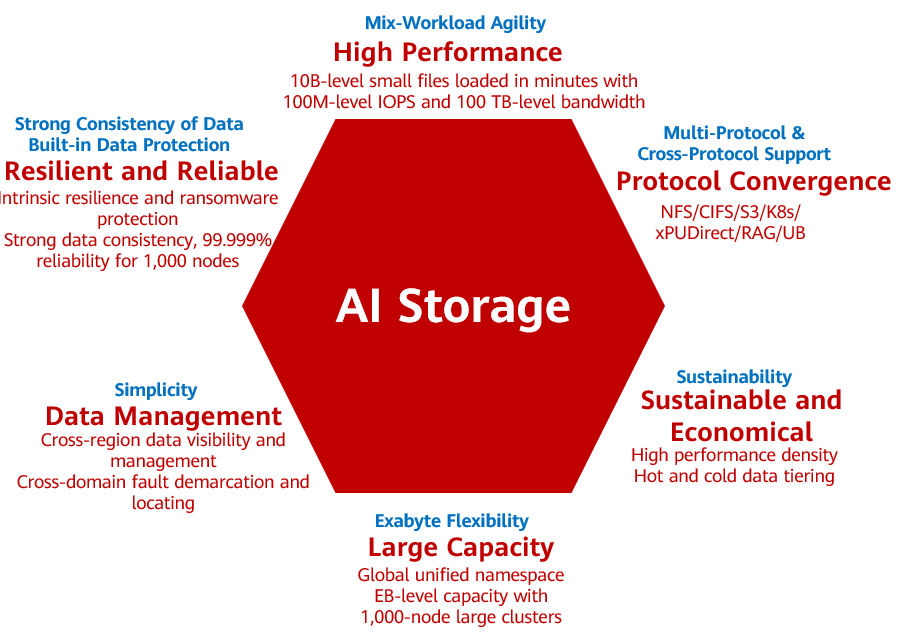
Figure 1 Resilience and reliability are key features of an AI storage
3. Data Backup Is the Most Effective External Measure
The most common external measure is efficiently backing up mission-critical data, typically achieved using industry-standard backup appliances. In AI environments, these appliances must go beyond traditional capabilities to address the challenges of large data volumes, high protection costs, and operational difficulties.
All-flash media accelerate data protection for large AI models. In recent years, the storage capacity of individual SSDs has seen remarkable advancements, with some now reaching up to 61.44 terabytes—three times the capacity of traditional HDDs. With their vast capacity and superior performance, SSDs are emerging as the optimal choice for accelerating data backup in the AI age. The Huawei OceanProtect Appliance, built on 30.72/61.44 terabytes SSDs, improves backup and recovery performance by more than three times than traditional solutions, meeting strict backup time window requirements.
Enhanced algorithms improve the data reduction ratio of the backup appliance. The continuously updated reduction ratio algorithms built on source deduplication and target-based deduplication facilitate to reduce the total cost of ownership. Huawei OceanProtect Appliance supports a data reduction ratio of up to 72:1 and is evolving to a ratio higher than 100:1. In petabyte-level backup data environments, the Huawei device maximizes the backup storage space by reducing the cabinet footprint in the data center, slashing power consumption and achieving energy saving and emission reduction.
Data anonymization ensures AI data resilience: In the AI age, privacy is always at the risk of leakage. Before backup data is reused, sensitive data such as names, IDs, and passwords must be anonymized to reduce the risk of private data leaks, ensuring the resilience of backup data during reuse and meeting compliance requirements such as PCI-DSS and HIPAA.
4. Internal Measure Should Focus on Intrinsic Resilience Protection
The internal protection should underline the intrinsic resilience capabilities of data infrastructure. This can be realized through two key approaches: first, native protection of storage system. For instance, ransomware detection ensures the reliability of AI data sources. Second, a multi-layer in-depth defense solution that is built on the collaboration of network and storage offers robust protection for large AI models.
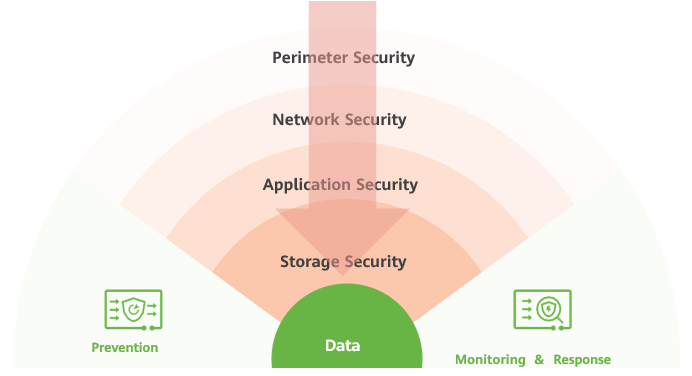
Figure 2 Network-storage collaboration provides robust in-depth protection for large AI models
Advantages of a multi-layer in-depth defense system:
Swift network-storage collaboration: If an intrusion is detected on the network side, an alarm is triggered and sent to the storage system. The storage system then takes corresponding protection measures, such as secure snapshots or network disconnection to an isolation zone, to respond quickly to different threat levels (high, medium, or low).
Accurate honeyfiles: Traditional storage-layer defenses rely on blocklists, trustlists, and post-incident scans to counter ransomware attacks. Honeyfiles, however, simulate sensitive data to proactively identify ransomware and trigger alarms before an attack occurs. This approach shifts from reactive response to proactive defense, enhancing protection and enabling precise detection.
Reliable in-depth defense: The multi-layer in-depth defense system extends the analysis of ransomware attacks, maximizing each defense line's detection and identification capabilities. The separated backup copies provided by the backup appliance and the isolation-zone copies facilitate to identify, prevent, and recover from malicious attacks, effectively ensuring data resilience. The Huawei solution that brings together networks and storage uses six layers of defenses to achieve a 99.99% ransomware attack detection accuracy.
5. Internal and External Data Protection Powers AI-driven Industries
As large AI models continue to evolve, their parameter scales and data volumes increase exponentially. In this context, data reliability and resilience are paramount. A comprehensive data protection system that integrates both internal and external measures is essential for supporting the training of petabyte- to exabyte-scale data, ensuring accurate training outcomes, and ultimately enabling AI-driven industry applications.
Disclaimer: Any views and/or opinions expressed in this post by individual authors or contributors are their personal views and/or opinions and do not necessarily reflect the views and/or opinions of Huawei Technologies. For details about Huawei products and technologies, visit the product and technology introduction page or contact Huawei technical support.
