
 Reprint
Reprint Lie 1: With the advent of 5G era, operators have increased their basic business significantly.
The penetration rate of 5G is continuously increasing. Although DoU (average monthly Internet traffic per household) has increased 6 times, the prosperity of 5G has not brought significant revenue increase to operators. Because traditional basic services have been seriously homogeneous, plus the requirements of & ldquo; Speed up and reduce fees & rdquo;, with & ldquo; Selling traffic & rdquo; for a typical traditional business, it has not increased for many years, and it is even more hopeless to achieve sustained and substantial growth through traditional business.
AI, cloud computing, big data, Internet of Things, quantum computing and other new technologies emerge one after another, pulling operators to invest in digital transformation. However, due to the different investment densities of operators, the progress of digital transformation is also uneven. Based on the revenue data of global operators in 2022, two kinds of portraits are generated. One is & ldquo; Robust & rdquo;, which still focuses on the traditional basic business of selling pipelines, with the development of 1 + N innovation and income increase around the network, the digital business has not yet formed economic benefits, its overall revenue growth is weak, and the digital business even has negative growth, such as AT&T in the United States, T-mobile in Germany, Singtel in Singapore, etc; and another & ldquo; Excellence & rdquo;, has begun to enjoy the results of digital transformation investment. Diversified emerging businesses are born, leading the main battlefield of business from traditional ToC to branding, driving the overall high-speed growth of revenue, such as China's three major operators, South Korea KT, Japan's KDDI, Thailand's Ture, etc.
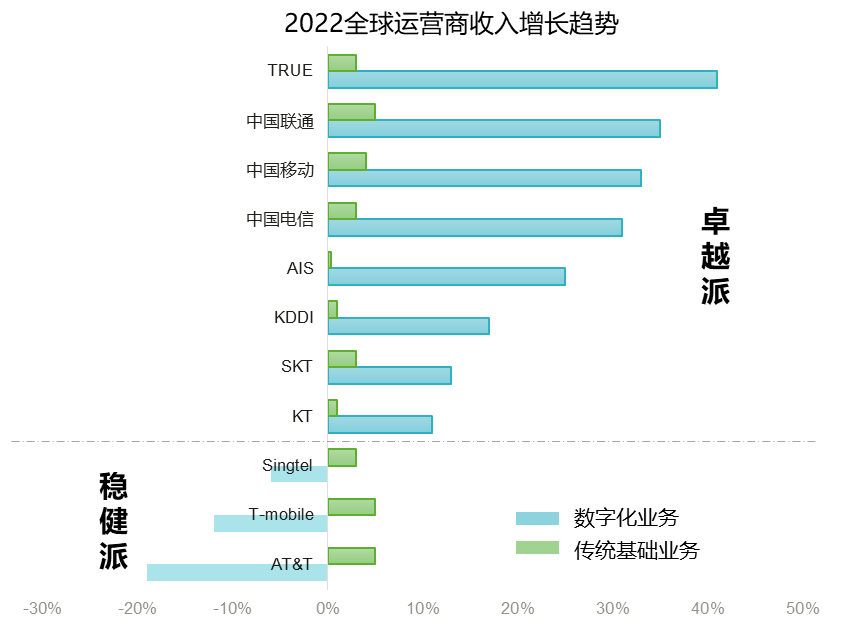
Truth 1: The growth rate of basic business is slow, and the income from digital transformation is the income of operators. Fastest engine
in 2023, the State Council issued the overall layout plan for the construction of Digital China, accelerating the process of Digital China and aiming to enter the forefront of the world by 2035. As the main force of Digital China Construction, operators have always been at the forefront of digital construction. Based on the "economic operation of communication industry in the first half of 2023" issued by the Ministry of Industry and Information Technology and the financial report of Chinese operators in 2023H1, & ldquo; Excellence & rdquo; The report card of operators in the first half of 2023 is as follows:

1. The growth rate of traditional basic business is weak: Under the circumstance that the growth rate of global operators' revenue is stagnant, the overall revenue of Chinese operators has increased, but among them, the growth rate of basic services such as fixed network, mobile and voice is slow, only 2% to 3%, far below the overall revenue growth of operators
2. The growth rate of industrial digital income is fast and the proportion is increasing.: Operators' Digital Transformation Revenue has maintained double-digit growth, and its proportion in the overall revenue has also continuously increased, with mobile increasing to 29.3%, telecom increasing to 29.2%, and Unicom increasing to 25%. This includes the new ToC market business represented by mobile cloud disks, the smart home value-added business typical of IPTV in the home market, and DICT, Internet of Things, leased lines, AI, revenue from emerging markets such as cloud computing and Internet access.
Lie 2:& ldquo; Cloud reform & rdquo; The wave is coming, and the carrier cloud transformation drives all business and data to the cloud.
The cloud transformation of operators has two goals : 1. Reduce costs and increase efficiency internally, the ICT infrastructure construction and operation of the current network are heavy, and cloud-based architecture is needed to improve resource utilization and reduce costs for ICT. 2, external empowerment, build an industry-level service system through cloud services, assume the responsibility of the digital transformation of the whole society, and help the digital and digital transformation of the digital economy society.
In the process of cloud-based implementation, stable core services such as CRM and Billing are still deployed offline to meet the requirements of high performance and low latency. However, sensitive services such as development and testing, Web Server, it requires more agile and flexible resources. The application ecosystem is close to cloud-native and is more suitable for cloud deployment. Then the question arises: after the business is deployed in the cloud, will the data be stored in the cloud?
Truth 2: it is urgent to defend data sovereignty, and the key data gathering offline is the cloud reform. Best Choice
countries all over the world have launched the & ldquo; Battle for data sovereignty & rdquo;, because data has not only become the means of production for new businesses such as AI and big data, but also is the core asset of enterprises. & ldquo; Will money be deposited in your own vault or distributed to various places? & rdquo;, this problem needs to refer to four key factors:
1. Regulations require data not to go abroad: Many countries have successively issued data protection laws (EU GDPR, China PIPL, Brazil LGPD, South Africa POPI), making it clear that data will not go abroad. If an enterprise violates data regulations, it may incur huge fines and other legal consequences. In May 2023, due to suspicion that Facebook, a social media platform, transmitted EU user data to the United States, the EU issued a 1.2 billion euro & ldquo; Sky-high ticket & rdquo;, for violating privacy regulations;, and ordered the company to stop transmitting data from European users abroad before October this year. Coincidentally, in 2022, the European Union also issued similar tickets to AWS and Chinese enterprise TikTok. Therefore, EU GDPR is also called & ldquo; The most stringent data protection act in history & rdquo;.
2. Unclear sovereignty over public cloud data: In 2018, the United States passed the & ldquo;CLOUD Act & rdquo; Challenge data sovereignty and require American enterprises to provide company-controlled data, no matter where the data is stored. For example, the U.S. government asked Microsoft to provide e-mails stored in Ireland. This solution has been boycotted by many countries around the world and said that it needs to replace cloud service providers such as AWS, Azure and Google in the United States through Sovereign Cloud.
3. High storage costs of public cloud data: as the amount of application data increases, the cost of cloud storage services will gradually exceed the cost of self-built storage. Take a three-year cycle as an example, the cost of local data storage is only 50% of the cost on the cloud (local $0.1/GB vs Cloud $0.22/GB), such as TikTok, enterprises such as Pinduoduo trigger data migration on the cloud after the data scale. However, the high cost of data migration on the cloud makes & ldquo; Easy to go to the cloud, difficult to go to the Cloud & rdquo; it has become a common pain point.
4. Data sharing between third-party public clouds: each cloud vendor has its own advantages in cloud services, such as AWS containers, blockchains, Azure Teams, and office. However, each public cloud has a serious awareness of data barriers, data cannot flow and be shared. There is no data that can be shared, and multi-cloud applications with their own advantages cannot be used.

To sum up, in the process of cloud evolution, operators should not only enjoy the convenience brought by cloud applications, but also consider data security and medium-and long-term use costs. Therefore, the optimal architecture for cloud evolution should be: applications are deployed in the cloud and synchronized locally. Data is stored locally and desensitized to the cloud as needed. In this way, safe, reliable and compliant professional storage is the best for local data storage & ldquo; Safe & rdquo;.
Lie 3: public cloud is innovative and efficient, and operators will work with third-party public cloud to achieve & ldquo; Win-win & rdquo;
public Cloud vendors all over the world have their own innovative heights, such as AWS's huge tool set, Azure's hybrid Cloud interaction, Google Cloud's AI and data analysis, etc. Enterprises can use the combination of & ldquo; Cloudy & rdquo; To achieve innovation and efficiency. According to statistics, 89% of enterprises in the world have cloudy strategic plans, and enterprises are actively embracing cloudy, accelerate innovation in a cloudy world. However, unlike most enterprises that directly use public cloud to support business evolution for a long time, operators mainly rely on their own channel advantages to resell such services by third-party cloud services & ldquo; Make quick money & rdquo; for example, operators such as Verizon, dedian DT, Globe, and True are keen to resell AWS cloud services such as DevOps and big data. They also bring products to Microsoft's Teams, office 365 and other mainstream Office collaboration cloud services.
Why do operators dislike long-term use of third-party cloud services?
Because, the goal of large operators is to become public cloud providers.. TOP operators have won the starting line of & ldquo; Cloud Services & rdquo; By relying on the far-leading 5G network technology, mature large-scale infrastructure, and the blessing of national policies. Taking Chinese operators as an example, SASAC pointed out in the "central enterprise deepening professional work conference" that operators will be the builders of national infrastructure and provide resources to the whole society in a unified way. The three major operators rely on unique & ldquo; Cloud-network integration & ldquo; Capabilities, and match national & ldquo; East and West Computing & rdquo; Strategies to carry the construction of national cloud data centers, through self-built public clouds and cloud services, we can empower thousands of industries and accelerate the digitization process in various industries.
Truth 3: The three clouds of the soaring operators have become public clouds in China maximum player
1, public cloud investment continues to increase: The investment of operators' cloud services is increasing year by year. Take a domestic operator as an example, the industry digital investment (including cloud services) accounted for 38% of the total investment in 2023.

2. The revenue of Sanduo cloud is increasing, and it has entered the top 5 of the market.: Chinese operators' high investment in self-built public clouds has also received positive market feedback, and the revenue of cloud services is moving towards & ldquo; Positive cycle & rdquo;. According to the H1 financial report of 2023, the public cloud market of the three major operators grew rapidly, with Tianyi Cloud's revenue of 45.9 billion yuan, up 81%, close to the revenue of 49.7 billion yuan, which has long been the top 1 in the list, 2023 annual Tianyi Cloud Challenge & ldquo; Hundreds of billions & rdquo; Revenue target unshakable, it is expected to grab the top of China's public cloud revenue list. The revenue growth of mobile cloud and Unicom Cloud, which followed closely, reached 63% and 36% respectively, far exceeding the industry average (8%). In 23, H1 operator Sanduo cloud entered the top 5 of revenue, entered the first echelon of China's public cloud market, succeeded in taking over the Internet cloud, and became the industry of government affairs, education, medical care and so on & ldquo; the public cloud provider of the state-owned enterprise cloud project & rdquo.

Lie 4: data will enter the YB era. The traditional full-stack server architecture is suitable for building data bases.
Data is the foundation of cloud services. With the digital transformation of services, data is growing exponentially. 5g and cloud-driven operators have tripled the number of calls and 10-fold the number of calls. According to the Digital China development report, by the end of 2022, China's data storage volume had reached 724.5EB, up 21.1% year-on-year. In the process of creating a data center that meets the needs of the cloud era, the explosive growth of these massive data has made efficient data storage a major problem.
We found that currently large-scale cloud data centers generally adopt the storage solution of server local disks and distributed software. This solution has the advantages of being lightweight and convenient, and can help build systems quickly. However, as the data volume increases sharply, this integrated storage and computing solution is not applicable to large-scale cloud data centers. For example, a large-scale cloud data center has a large number of local disks, but the server does not have professional management capabilities for hard disks. When a hard disk problem occurs, it will cause slow response and will soon become invalid, it consumes a lot of CPU computing power when reconstructing the upper-layer distributed storage software, which has uncontrollable impact on the business. For another example, to ensure reliability, a three-copy storage policy is usually adopted, that is, one copy of data is stored in three copies, the storage space utilization rate is only 30%, and the cabinet space and energy consumption are large.
Truth 4: Cloud is decoupled in layers. Diskless is a large-scale public cloud system. Optimal architecture
1, cloud data center architecture has moved from closed Full Stack to open cooperation. In terms of technology trends, the advanced public cloud system architecture has changed from full stack to hierarchical decoupling (such as AWS and Azure), and has cooperated with the industry's best products for integration and hierarchical construction, find the Business & ldquo; Optimal solution & rdquo; With an open attitude;.

2, professional storage based on Diskless Diskless architecture can better reduce space and energy consumption, and simplify hard disk management and maintenance.. For the IT infrastructure facing massive data, how to realize the expansion of storage and computing power on demand has also become the key to operators' IT innovation. Therefore, the Diskless architecture with the new concept of separation of storage and computing came into being. The Diskless architecture supports resource pooling, which completely decouples the original multi-level layered resources from pooling, reorganizing and integrating, and realizes independent expansion and flexible sharing of various hardware types. For example, if the data disks in the server are pulled away, the hard disks are centralized in professional storage for unified management, and technologies such as sub-health management of native hard disks and slow I/O response of third-level hard disks are adopted by professional storage manufacturers, prevents underlying hard disk failures, maintains the reliability and stability of massive hard disks in large-scale data centers, and greatly reduces O & M difficulties. At the same time, through key technologies such as data reduction and large proportion EC, the storage efficiency is improved, the resource utilization rate is improved, and the cabinet space and equipment power consumption are reduced.

In China, a head operator has applied the Diskless storage and computing separation architecture to the construction practice of intelligent computing centers, using professional storage to reconstruct the data base of private and public clouds, it is applied to emerging scenarios such as automatic driving, industrial intelligent manufacturing, and AI painting. The overall performance is improved by 2 times, the computer room occupancy rate is reduced by 40%, and the business interruption caused by hard disk failure is shielded, O & M is more cost-effective.
Lie 5: Big models set off performance requirements, while operators have strong computing power, AI is strong.
AI outbreak, operators enter & ldquo; 100-model War & rdquo;. OpenAI predicts that 50% of human work task scenarios will be affected by ChatGPT in the future. As the builders and operators of information and communication infrastructure, operators will not only provide infrastructure support for the development of AI, but also be the pioneers of AI applications. When fully embracing new AI opportunities, operators will give full play to their existing data advantages, resource advantages, and industry-enabled experience advantages to build a leading AI infrastructure, relying on the integration of computing networks, AI services can reach everything, thus leading the development of the industry.

Generalized computing power = computing power & & storage power & & capacity. To seize the development opportunities of large models, operators must first build leading AI infrastructure. The parameters and data size of large models are increasing exponentially. In addition to the extremely high computing power requirements, they also require higher storage scalability, performance, and latency. For example, during the data loading and storage phase before and after a training batch, if the access performance is insufficient, valuable computing resources will be wasted. Qu Guangnan, an academician of Chinese Academy of Engineering, pointed out & ldquo; Capacity, computing power and transportation power are indispensable. Only by balanced allocation and balanced development of the three can we give full play to the role of computing power & rdquo;. It can be said that saving power is the premise and foundation of computing power value.
Truth 5: lack of data and AI, only with strong computing power can AI be built strongest base

data determines the height of AI intelligence.. Big models must serve thousands of industries for intelligent upgrades. Data quality and scale determine the competitiveness of operators in AI. As the carrier of data, AI has the ability to inject a steady stream of data & ldquo; Fuel & rdquo;, and install dynamic data & ldquo; Engine & rdquo;, provide reliable data & ldquo; Shield & rdquo;.

For large model scenarios, server storage is insufficient, general storage is not easy to use, and customized AI professional storage is required. The development of AI technology has gone through the traditional AI era, the deep learning era and the big model era, and the required memory systems are also evolving. In the traditional AI era, researchers try to use symbols and rules to implement artificial intelligence. The training scale is limited and the data is mostly structured data. The storage method is local storage. In the era of deep learning, the training data of deep neural networks are mostly single-modal data such as text, images, and audio. As the training complexity and scale increase, a unified data resource pool is needed to realize data sharing, in this case, the I/O performance of data is not high, mainly object storage. At present, AI has developed into the era of big models. The traditional object storage resource pool built by server clusters can no longer meet the requirements. For example, when a smart computing center cluster runs a 65B big model, the read/write bandwidth of 1PB object storage is only 2.4~7.5Gb/s, resulting in frequent training failures. Facing the large model of trillions of parameters and PB-level training data, the storage system needs to build professional AI storage for this purpose, which usually requires the construction of & ldquo; High-performance layer + large-capacity layer & rdquo; the AI storage cluster is called & ldquo; Advanced AI storage & rdquo;.

Only by constructing advanced AI capabilities can operators be released with the strongest & ldquo; Generalized computing power & rdquo;. The continuous innovation breakthrough of big models requires the optimization of the whole AI process from the perspective of data, and the full combination of training data, industry-specific knowledge base and big model capabilities through advanced AI capabilities, to accelerate the scenario-based big model service, you can use the cost-based computing method to achieve thousands of businesses. First, in the data collection phase, it is necessary to efficiently process PB-level diversified raw data collected by multiple regions and branches. Second, during model training, large amounts of small files need to be randomly read and model data sets need to be saved quickly. Finally, incremental source data and vector data need to be retrieved quickly during model reasoning. These challenges require innovative AI storage solutions, such as intelligent data weaving to achieve global unified data View and scheduling across systems and regions. Through near-memory computing, uninstall some data preprocessing capabilities, reduce data migration, and shorten data preparation time. Through all-flash distributed storage, tens of millions of read/write times Per Second (IOPS,Input/Output Per Second) of storage nodes are realized. And hundreds of GB/s bandwidth to improve training efficiency; High-performance vector retrieval capability is realized through vector storage.
Lie 6:& ldquo; Double carbon & rdquo; Become a hard indicator, operators rely on & ldquo; Reduce PUE & rdquo; Achieve energy conservation and emission reduction
according to the latest report of GSMA(Global System for Mobile communications Association) in 2023, 62 operators worldwide (accounting for 61% of the industry's overall revenue) have promised to achieve the goal of rapid emission reduction by 2030. Under the background of & ldquo; Carbon peak, carbon neutralization & rdquo;, green and low carbon have become an important development direction of operators' data centers, while PUE(Power Usage Effectiveness) it is generally considered to be the most important indicator to evaluate the energy efficiency of data centers.
The Calculation Formula of PUE is & ldquo;PUE value = total energy consumption of data center/energy consumption of IT equipment & rdquo;, the lower the PUE value, the lower the energy consumption of non-IT equipment in data center, the more energy-efficient the data center is. The energy consumption of data centers usually includes IT equipment, refrigeration system, power supply and distribution system and others. Taking a data center with a PUE of 1.5 as an example, the energy consumption of IT equipment accounts for about 67%, refrigeration system accounts for about 27%. Refrigeration system is the largest energy consumption besides IT equipment, so optimizing refrigeration system is the main way to reduce PUE.

Proportion of power consumed by each component in a data center with PUE = 1.5
there is no doubt about the importance of PUE, but PUE cannot comprehensively and truly evaluate the energy saving situation in data centers. For example, by improving the efficiency of IT equipment and greatly reducing the energy consumption of IT equipment through energy-saving technologies, the total energy consumption of the data center will also be reduced. Because the two are not simply linear, the PUE of the data center will increase instead. & ldquo; Double carbon & rdquo; The ultimate goal is to achieve energy conservation and emission reduction, rather than PUE-only.
Truth 6: two-pronged approach, & ldquo; Reduce PUE + reduce power consumption & ldquo; Combine boxing to achieve minimum energy consumption
IT equipment is the largest source of electricity during the operation of the data center. Therefore, IT is an inextricable link for the data center to further save energy and reduce emissions and reduce the power consumption of IT equipment. Among them, storage power consumption accounts for more than 30% in data centers and is becoming the facility with the fastest power consumption growth among IT devices. To achieve the goal of green energy conservation, operators' data centers need:
1. From focusing on the reduction of PUE to focusing on the reduction of storage power consumption
the annual power consumption for storing 1PB of data in the data center can reach 300000 kWh, equivalent to 235.5 tons of carbon emissions. The global data volume will reach 180ZB (about 0.18 billion PB) in 2025, three times that of 2020. In order to save these data, the storage power consumption will increase significantly. By 2030, global data center storage carbon emissions will easily exceed global carbon emissions in 2019. Therefore, operators' data centers need to implement & ldquo; Dual carbon & rdquo;, in addition to reducing PUE, more attention should be paid to how to reduce the power consumption of storage devices.
2. From focusing on maximum storage power consumption to focusing on energy efficiency indicators
when purchasing storage, operators usually take the maximum power consumption of the equipment as the evaluation index of whether it is green and energy-saving, but the maximum power consumption is generated when the equipment is running at full load, which is not the normal state in the actual use process, the storage efficiency cannot be reflected. Global Association of network storage industries
Storage Networking Industry Association , capacity/W, IOPS/W, bandwidth/W as an energy efficiency indicator, it can truly reflect the performance and power consumption of devices under different IO models. This specification was adopted as an international standard by ISO/IEC in 2019. the energy efficiency index of SNIA will also be used in the storage energy efficiency standard issued by ETSI of European Telecommunications Standardization Association and China Standardization Research Institute in 2024.
Focusing on energy efficiency indicators is conducive to the healthy development of energy-saving technologies in the storage industry. Operators can achieve optimal energy consumption per bit of data under the same capacity and performance requirements by selecting energy-efficient storage devices, thereby reducing the overall power supply burden and reducing carbon emissions in the data center.
Lie 7: data is the core asset, and network security is the moat of operators' data.
Currently, based on a series of network security products such as firewalls and intrusion detection systems, operators have built an integrated network security comprehensive defense system such as perception and early warning, comprehensive detection and emergency response. Prevent attacks, intrusions, damages, illegal use and accidents of the network, keep the network in a stable and reliable operation State, ensure the integrity, confidentiality and availability of network data, and thus protect data security.
However, with the iterative leap of AI technology, Hacker technology and attack methods have been continuously improved, and network security incidents in the telecommunications industry have occurred frequently. For example, Beeline, a Russian telecom company, was hacked in 2019. 8.7 million of its customer data was leaked and sold online. AIS cloud, Thailand's largest mobile operator, disclosed 8.3 billion Internet records in 2020, data is used to map user network activities. The strong network defense system of operators cannot ensure that data is safe under new forms of attacks.
Truth 7: there must be a secret on the internet. Storage is the last line of defense to protect data security.
With the rise of emerging technologies such as AI, 5G, and the internet of things, the UED business is booming. Due to the large number of network exposed nodes and the need to transmit large amounts of data, the boundary of network information security is weakening. In addition, data & ldquo; Poisoning & rdquo; Is increasingly rampant, and the network layer cannot achieve 100% perceived interception.
Judging from Northrop & middot; Grumman's defense model in depth, the attack of virus starts from the network first. When it breaks through the blockade of the whole network, that is, after breaking the boundaries of the whole network security, the host will attack the application permissions. Once the permission is obtained, the target is the final core asset, that is, data. Because blackmail viruses are good at disguising, invading through loopholes, phishing, internal ghosts, etc., they have a long latent cycle. Even if the network layer can intercept 99% of ransomware viruses, 1% of attacks will flow into the storage layer, resulting in data security risks.

Northrop & middot; Grumman deep defense model
in recent years, the potential of storage data security has been continuously explored, such as the on-disk encryption solution to protect data confidentiality, ransomware detection and recovery technology to protect data availability and integrity, WORM, security snapshots, disaster recovery and archiving. Disk-down encryption can solve the problem of data leakage after the storage media is stolen. The anti-ransomware solution is based on the statistical characteristics of the data (such as entropy changes and re-deletion compression ratio) to determine whether data is being encrypted in large quantities. Compared with network and host-side security solutions, storage systems have unique advantages in protecting data AT REST (static) states.
From data generation, data transmission, data storage, data backup, to data destruction, data security is accompanied by the entire lifecycle of data. Storage is the ultimate destination of data. We only need to start from the destination and establish a systematic and system-wide data security solution where the data is and where the security radiation is based on the collaborative network, storage and calculation, to solve the real pain points of data security.
To sum up, as the final carrier of data, storage is the last line of defense to protect data security. Through the storage hardware and software capabilities, the system can not be broken through, data can not be changed, and business can be restored. This ensures that data & ldquo; Is always available & rdquo;, avoid the economic, reputation, Justice, personnel changes and other impacts on enterprises when data security problems occur.
