
 Reprint
Reprint With the rapid development of distributed database technology in China, the separation of storage and computing has always been a hot topic. For a distributed database, what kind of separation of storage and computing is the correct posture.
The origin of separation of storage and calculation: Cost reduction and efficiency improvement
everything should start with the digital transformation of the enterprise. The digital transformation of enterprises is a systematic project, and the transformation of distributed databases is a very important one. Here are two core Keywords: Distributed and database ". "Distributed" means the ability to meet the horizontal expansion of large-scale clusters and provide cloud-native services; the database includes two requirements: high availability of persistent data storage and high availability of data access services.
Seeing this, my friends may not feel that there is any problem. After all, it seems that it is not difficult to build a distributed cluster with multiple servers, and there are many open source solutions. But if we dig deeper, it seems not that simple.
For most distributed cluster solutions, database instances are synchronized through log replication. Because the data between instances is managed by each other, several instances need to have several copies of data on the hard disk. Otherwise, how many copies are needed to ensure data reliability, the number of instances that must be run. Therefore, this binding relationship, whether hard disk or server, must be configured according to the maximum specification. This is really rich and willful!

The problem that money cannot solve: the constraints of the integrated storage and computing architecture lead to the inability to flexibly expand
all the problems that money can solve are "not problems". Let's put them aside for the time being and talk about other technical problems first. Let's start with containerization and resource pool. Directly put the database in the container, has the containerized transformation been completed? Things are definitely not that simple. Because the copies of the database are fixed on several servers, failover cannot be balanced in the entire resource pool, but is limited to these specific servers.

As shown in the preceding figure, switching seems to be possible. However, no server can be used as the switching target unless data cloning is performed in advance. For the resource pool construction target, flexibility is obviously insufficient.
The real trouble is to expand capabilities. At this point, we have to talk a little bit about the issue of multiple copies of data. As mentioned earlier, the current solution is that the database builds multiple replicas on multiple servers to implement data redundancy. How can data consistency be guaranteed between servers that make up multiple replicas? Some friends have already thought of using Paxos. Yes, this is what some current solutions do. Let's put aside the complexity of the Paxos algorithm implementation itself. As long as Paxos (or Raft) is used, it means that every time you want to make a change, everyone must initiate a vote to win the support of most people. OMG, can this be fast! To make matters worse, multiple nodes may initiate a change vote at the same time to request support from the other party, which may lead to competition or even conflict with the same resource. OMG , again! Forget it, or we don't need Paxos, just use a simple master-slave copy. What are you talking about? Master-slave latency, heavy business pressure, network convulsion can't guarantee data consistency, RTO can't guarantee? Can we still play happily?
After understanding the relationship between multiple replicas and some restrictions on implementation, it is not difficult for us to understand that the current scheme is actually a state in which the two pests are lighter. Alternatively, you can choose to perform read and write services on a node and accept the risk that data cannot be completely consistent between master and slave nodes (for example, MySQL master-slave mode), either choose to endure the election overhead, negotiation conflicts and even lock-up problems (such as MGR mode) caused by multiple nodes performing read and write services. When performance expansion is required, you cannot immediately add a batch of database instances to solve the problem, because the nodes where these instances are located have no data at all. That is to say, database instances are placed in containers, but cannot be freely scheduled, switched, and expanded.
So how to solve these problems mentioned above?
The first step towards the separation of storage and calculation: decoupling storage and calculation
first, we must break the binding coupling relationship between storage and calculation. Shared storage solves the problem that each instance's own data Copy cannot be shared, and allows the database instance to be stateless independently of the storage.

The deployment scheme is shown in the preceding figure. MySQL no longer has a local data disk, and all data is provided by the storage pool.
However, this only solves the problem that the database container must copy data in advance when drifting between multiple nodes. Although data is shared, three or more parts of data are operated by multiple different instances. Therefore, the consistency between these parts of data needs to be solved by the database layer. In other words, negotiation mechanisms such as Paxos and Raft are still essential, and the problems mentioned above have not been completely solved. In addition, if more MySQL instances are to be added at this time, more data copies are needed in the storage pool, and several copies are needed in the storage pool of several instances.
As mentioned earlier, you do not need to bind MySQL slave nodes and data replicas. As a result, there is a commonly used practice in the industry, that is, to allow the database instance to access the same logical data, and then the logical data corresponds to three fixed copies in the storage, in this way, the data copy has nothing to do with the database instance. In this way, no additional data copies are required between multiple instances.
However, if you can use this method, you need to modify the kernel implementation. Generally, it is claimed that it is compatible with the self-developed Kernel Database of the MySQL ecosystem, or some deeply modified cloud databases. Open-source MySQL databases cannot enjoy this benefit. But don't worry, we will discuss the solution later.

Step 2 towards separation of storage and computing: improve the efficiency of separation of storage and computing
now that data has been shared and decoupled from the number of instances, do you still need to copy three or more copies of data in the shared storage, occupying multiple times of space? In fact, if multiple copies of storage data (usually cross-storage node copies) are used, cross-network consistency must be solved between them, and cross-network negotiation must be introduced. In addition, we know that in order to write three replicas, the industry generally has two methods. One method is to send data from a computing node to a storage node, let's call this storage node "captain" for the moment. It coordinates the data of other storage nodes to be returned after all data is swiped. The obvious problem of this approach is that the "captain" has to do the second hand and return after collecting the results. The delay is too large. Another method is to send data directly from the computing node to the three storage nodes for disk brushing, and the computing node is responsible for the "captain" color correction for organization and coordination. In this way, the latency is lower than that of the previous method, but the data needs to be enlarged at least three times between computing and storage, and it is relatively complicated to handle the failure as the leader's coordinator. So now some customers will be told that they either choose low latency and high traffic, or choose to increase traffic hours, or they can only take advantage of the two damages.
In fact, since the database can already access the same logical copy, this logical copy only needs to ensure its high reliability. Making three copies of data is only one of the ways to achieve reliability, not the only way. At the same time, we should also consider avoiding the delay problem mentioned above.
The foundation of separation of storage and computing: enterprise-level shared storage technology provides a reliable base
here we will first introduce the high-availability power-saving memory and code correction technology. In fact, professional enterprise-level storage, both of which are standard housekeeping skills. Let's talk about erasure codes first. This technology actually uses a verification algorithm to calculate M redundant data blocks from N original data blocks and verify them quickly, forming N M data blocks. If no more than M data blocks are lost or damaged, the original N data blocks can be calculated. For example, if N = 8 and M = 2, 10 data blocks are calculated and distributed to 10 disks. At this time, no data will be lost if any two disks are damaged. However, if the replica-based method is to reach the same protection level, three replicas must be required, that is, at least 8x 3=24 data blocks must be generated, the space occupied by data blocks will be 24/10=2.4 times that of the erasure technology.
Let's talk about the high-availability guaranteed memory. As the name implies, it is the memory that will not lose data when the power is down. In addition, the hardware design based on professional storage can support cross-node protection and zero detection of storage node failure Services (this part of technical details have public information, which will not be discussed in this article). With this, data is written to storage, in fact, it only needs to be written to memory, which is basically the delay of network transmission. In addition, the backend of the power-saving memory performs code correction and disk brushing on the data. This also brings another advantage that data can be used to brush disks in large blocks. We all know that when a hard disk is continuously swiped, its performance is several times higher than that of a small random disk.

You know, the storage products equipped with these two technologies are now systems that run in the core applications of finance or operators all the year round, and are already quite mature technical solutions. It is no exaggeration to say that the money in our bank card is likely to exist in this level of professional storage now.
Use of memory and computing separation: seamless and smooth replacement, simple and easy to integrate
this method looks great. Data is shared and replicas are unified. However, as mentioned earlier, multiple instances of an open-source database cannot access the same copy online. This was true in the past. After all, the running logic of database instances was that data changes either came from operations at the business layer or from synchronization caused by logs, the shared copy means that data changes have a third source, that is, the data itself is directly modified by another instance. But it doesn't matter, this is also a key point we are going to talk about.
To enable open-source databases to achieve real decoupling of storage and computing, and to access shared storage data by multiple instances, we have built a storage acceleration layer to implement strong consistent read and write of data between primary and secondary instances. The main problem of this storage acceleration layer is that when multiple nodes have read and write, the data views between nodes are always consistent. On this basis, in fact, there is no delay between the master and slave nodes, and the Slave node can read the data changes of the master node in real time. This acceleration layer can be directly connected to the current open source database through plug-ins, without modifying any code, and the running database does not need to be recompiled. It can be used after simple configuration, is it very convenient?
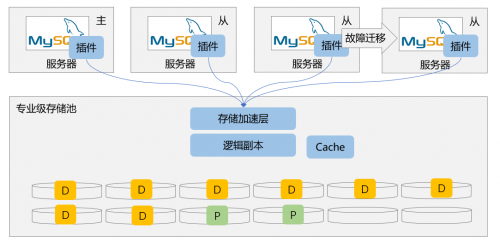
Ultimate separation of storage and computing: Multi-read and multi-write services
if both the master and the slave have achieved strong Cache-level data consistency and no master-slave latency, is it possible for the Slave node to directly receive read and write requests instead of only read-only requests, that is, all MySQL instances become "master nodes"? The answer is yes, of course!
In fact, this innovation is crucial to the transformation of distributed databases. This means that we can pull up containers of multiple database instances from any server at any time to support our business. This is the real business that is bounced on demand. Oh, it is not just bounced on demand. Because the previous slave nodes that Stand by have become the master nodes that can receive business, the improvement of work efficiency is just the same. If the efficiency is improved, there is no need to idle as many computing servers as before. The extra server is very powerful. Why is it not good. Of course, on the basis of strong consistency, the technical difficulty of implementing multi-write and some multi-read is not on the same level at all. Fortunately, Huawei Enterprise Storage has now completely solved this problem.

So far, the goal of transforming the distributed database has been basically achieved.
To sum up:
1. The binding relationship between storage and computing is an obstacle to cost and business flexibility, so the separation of storage and computing is an inevitable trend in the industry;
2. After separation of storage and computing, improving storage efficiency and performance is the core; Under the premise of high availability, normalization of multiple replicas while providing extreme latency access is the key to competitiveness;
3. The separation of storage and calculation and sharing of data have laid the foundation for strong consistency between primary and secondary, and can further realize multi-master and multi-write. However, multi-master and multi-write computing is truly stateless, allowing you to pull up instances and deploy and expand your business at will;
4. The key to the transformation of the distributed database is that the kernel does not need to be transformed, and the storage acceleration layer can smoothly connect to the existing system for business.
