 转载
转载 近日,拜访一金融客户,反馈说,某国产数据库上生产后,因为一块NVME SSD盘超时导致业务Hang住了长达6分钟多,导致业务中断。分析日志发现是NVME SSD hang住了,IO进入linux块设备超时处理机制,通用的OS的处理机制是这样的:
1)IO下发后默认超时时间是30秒,IO没有回来开始超时处理;
2)发起Abort此IO,告诉下层驱动及盘丢弃此IO,abort的超时时间30秒;
3)Abort失败进一步执行Controller reset通知SSD主控软复位,此操作超时时间12秒;
前面动作执行成功后会将此IO放入队列重试下发给盘,如果再次超时将再次进入超时处理流程。重试次数最多5次,也就是说IO在此hang住的时间就可能(30+30+12)秒*5次=7分钟,此段时间IO就无法返回上层数据库,导致整个RAID组均Hang住,业务就挂死。
其实这个是Linux OS块设备超时的大Bug,记得2009年存储后端系统就频繁出现这种IO超时挂死业务问题,14年前的问题没有想到在分布式架构大行其道的今天再次发生,因为大量的业务使用服务器本地盘,大量业务IO访问,有一张SSD盘超时或者BUG就导致整个业务hang死翻车,孰能容忍?
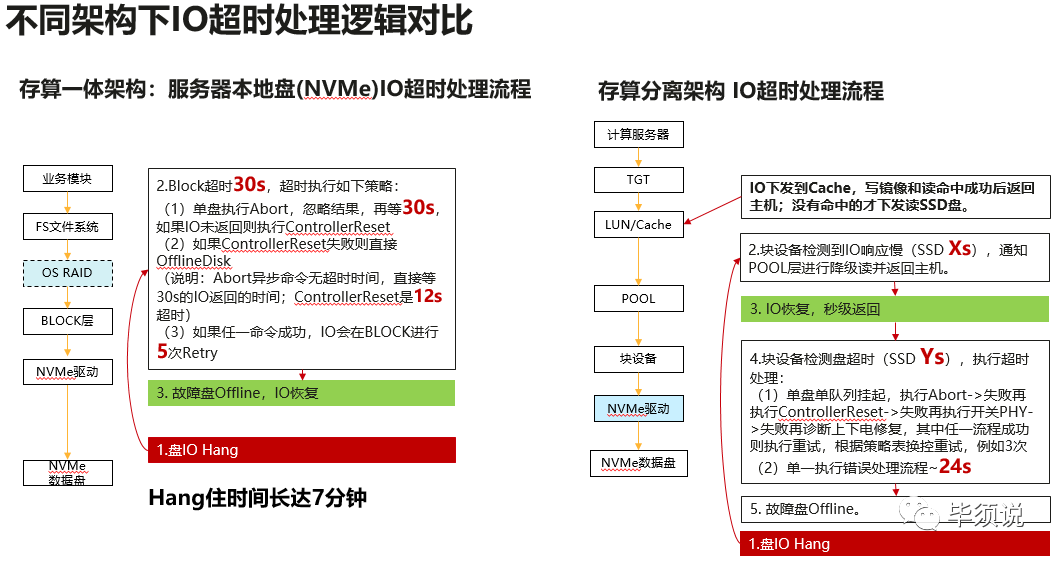
其实存储系统在14年前发现此BUG就做了改造,可靠性加固:
1)首先主机IO下发到存储系统在前端LUN cache实现了写镜像和读命中返回主机,部分不命中的IO才会下发访问盘。
2)最重要的是存储系统有检测慢盘机制,如果检测发现盘的IO超过几秒,就会启动存储RAID降级读写,通过RAID其它成员盘将数据计算出来返回上层,先保证业务恢复,再修复故障。
3)后台系统继续检测,
3.1)当这个盘IO超时达到Y秒(原来是30秒)就进入超时错误处理流程,
3.2)依然是先abort此IO(超时12秒),
3.3)如果失败告知SSD主控软复位,
3.4)还失败,就重新上下电硬件复位。成功复位后发命令检测IO时延是否正常,如果正常就接入系统,否则就执行隔离离线此盘。
所有这些错误处理流程都是后台执行,前端的IO通过RAID降级读写返回,先恢复IO再尝试修复,而不是按照通用OS的先修复故障再恢复IO,这样就不会导致业务Hang死。
所以当前分布式大量采用不可靠的服务器本地盘,而错误处理机制又没有改造,单块盘出现Hang死,系统消耗长时间去修复,导致业务中断。服务器SSD很多小厂家研发流程不规范,制造流程,来料品控问题,质量不过关,产生Bug就很正常。出了这种问题,数据库厂商会负责吗?还是服务器,OS,还是盘厂商来兜底呢?
或许数据库会说,下层hang住了几分钟,数据库层面检查探活机制,几十秒强切到从节点,就没有问题吗?这样主节点没落盘的,缓存的数据并没有完成落盘,会不会导致数据丢失呢?甚至数据不一致呢?这就更致命了。
下层挂住最佳的处理机制肯定是先恢复业务,再快速隔离,故障是快速收敛闭环,而不是因为一块盘故障扩散爆炸到节点级故障,会不会进一步把集群拉崩呢。而如果采用数据库+外置企业存储LUN就完美的解决类似故障,可靠性更高,利用率更高,性能时延更优,何苦用不可靠的服务器盘呢?这也是A国这套架构的核心逻辑,专业的人干专业的事,专业的领域需要专业的公司来持续不断做精通。
文章来源:毕须说

